XML DOM Engine Overview
The XML DOM Engine implements the standard DOM API (tree-based XML parsing and editing), including XPath and serialization extensions.
Purpose
The XML DOM Engine provides APIs to achieve the following:
Parse XML content: create a DOM tree from XML streams or files
Create an empty DOM tree
Modify a DOM tree by adding or removing nodes and changing their properties (attributes?)
Save a DOM tree to a buffer or a file (in regular XML, XOP or compressed format)
Explore a DOM tree with XPath expressions
Required background
The XML DOM engine is based on the libxml2 component. It provides a Level-3-like implementation of the DOM standard from W3C, along with XPath and serialisation extensions.
Key concepts and terms
The following concepts are related to generic XML understanding:
XPath Extension Functions
XML Path Language (or XPath) is a W3C standard designed to address parts of an XML document. A subset of XPath is also used for matching: that is, checking that a node matches a pattern. Extension Functions are not part of the W3C standard: you can implement them to add functionalities to XPath.
Serialise
Serialising means converting binary data to a persistent format that can be stored (to a buffer or a file) or transmitted over a data link. The reverse operation is called deserialising.
The RChunk and RHeap classes are standard Symbian platform classes. For more information, see Memory allocation concepts.
Architecture
The XML DOM Engine component relies on the libxml2 component for most of its operations. For more information, see libxml2 Overview.
It also relies on the libxml2 SAX parser plugin of the XML Framework and on the multi-part parser of the BAFL component for deserialisation.
The following package diagram summarises the dependencies of the XML DOM Engine and shows the three functionality groups that are described in the following section.
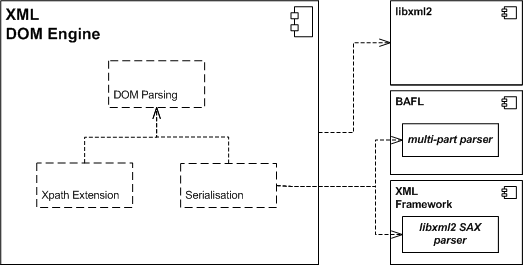
Figure: Package diagram for the XML DOM Engine component
Description
The XML DOM Engine is an object-oriented provider of the DOM services included in the standard libxml2 library: tree-based parsing with validation and random access to the XML elements. If you need event-based parsing, use the XML Framework instead.
DOM Parsing
Parsing an XML
document creates two parallel trees: the regular DOM tree containing generic
Node objects and an RXmlEngDocument object which contains
type-specific nodes. Use these type-specific nodes to avoid type-checking
and casting the Nodes as well as to improve performance. Some of these node
types are shown in the following diagram.
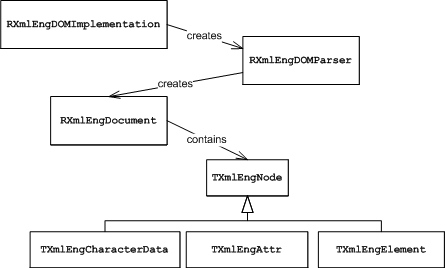
Figure: Extract of the class diagram for the XML DOM Engine parser
Serialisation
Serialisation transforms the DOM tree (including binary data) into one of the following formats:
Default (standard XML)
XOP (XML-binary Optimized Packaging)
XOP Infoset (original Infoset with any optimized content replaced by
xop:Includeitems)gzip (compressed XML)
The result can be returned as a file, a buffer or both.
XPath Extension Function
XPath can be extended at run-time by registering a new extension function. To call the new function, include it in an XPath expression evaluated by the XML DOM Engine.
The XPath Extension Function API provides two interfaces: MXPathExtensionFunction for the XPath function and MXmlEngXpathEvaluationContext for its configuration. The static TXmlEngXPathConfiguration class performs the registration of the extension function within the XML DOM Engine.
APIs
DOM Parser API
The most relevant classes for parsing and editing a DOM tree are listed in the following table. See Implementation of W3C Types for correspondance between this API and the W3C standard.
| DOM Parser API | Description |
|---|---|
RXMLEngDOMImplementation |
This class is the entry-point for the DOM Engine. It provides methods for creating a new document or an instance of the DOM parser. |
RXMLEngDomParser |
This class provides methods for parsing an XML document and building a DOM tree. |
RXMLEngDocument |
This class represents a DOM tree. It stores the document properties and provides methods for modifying the tree, such as adding or deleting nodes. |
TXMLEngNode |
This class represents a DOM node. It stores the node type and properties, and provides the DOM methods related to it. Specialisations of this class are detailed in XML DOM Engine Node Reference. |
The DOM API relies on Descriptor objects for string manipulation,
and on RFile handles for filesystem input and output. To
store RFile in a DOM tree, use the TXmlEngFileContainer class.
To store RChunk in a DOM tree, use the TXmlEngChunkContainer class.
Serialisation API
The most relevant classes for DOM serialisation and deserialisation are listed in the following table. Other classes can be found in the reference documentation.
| Serialisation API | Description |
|---|---|
This class provides methods to save a DOM tree to a file or a buffer. |
|
This class provides methods to read serialised XOP or GZIP and create DOM or SAX representations of it. |
XPath APIs
The DOM Parsing classes related to XPath are listed in the following table. Other classes can be found in the reference documentation.
| XPath API | Description |
|---|---|
This class represents an XPath expression. |
|
TXmlEmgXPathEvaluator |
This class evaluates an XPath expression and returns the result
in an |
This class contains static methods for XPath configuration and registration of extension functions. |
The most relevant classes of the Extension Function API for XPath are listed in the following table. Other classes can be found in the reference documentation.
Typical uses
The XML DOM Engine is used by client applications to process XML documents:
The most common clients are web browsers and associated software, which parse and validate XML streams or files.
Applications can also use the XML DOM Engine to organize and store their data, or to transfer their XML objects over a network connection.
Middleware providers can extend XPath with new functions with the XPath Extension Function API.
To port an existing application that uses the standard libxml2 library,
use the libxml2 component and call the C++ wrappers of the
standard library.
Here are some of the common tasks that applications perform through the XML DOM Engine:
Read an XML file by one of the following means:
Use the RXMLEngDOMParser class to parse a regular XML file and get a DOM tree, as explained in the XML DOM Parsing Tutorial.
Use the CXMLEngineSaxPlugin class to parse a regular XML file and get SAX events, as explained in the XML SAX Parsing Tutorial.
Use the
DeserializeL()</codeph> method of theTXmlEngDeserializerclass to deserialise a compressed XML file and get SAX events.Use the
UseDOMImplementation()andDeserializeL()methods of the TXmlEngDeserializer class to deserialise a compressed XML file and get a DOM tree.
Save an XML object to a file by using the TXmlEngSerializer class, as explained in the XML Serialisation Tutorial.
Search through an XML document with XPath, as explained in the XPath Tutorial.
Add extension functions to XPath, as explained in the XPath Extension Tutorial.